Recent Research Projects
Popularity and Success on Social Networks
In the Internet age, there are numerous platforms for disseminating text, images, and videos. Content with wide visibility are mostly shared by influential accounts on these platforms. Influence is commonly measured by number of accounts following or subscribed to content shared by those influencers. Here, we quantify the changes in influence, popularity, and productivity of accounts for a period. We model account trajectories using a stochastic model to uncouple effects of popularity and productivity from individual qualities quantified as social impact factor for each account.
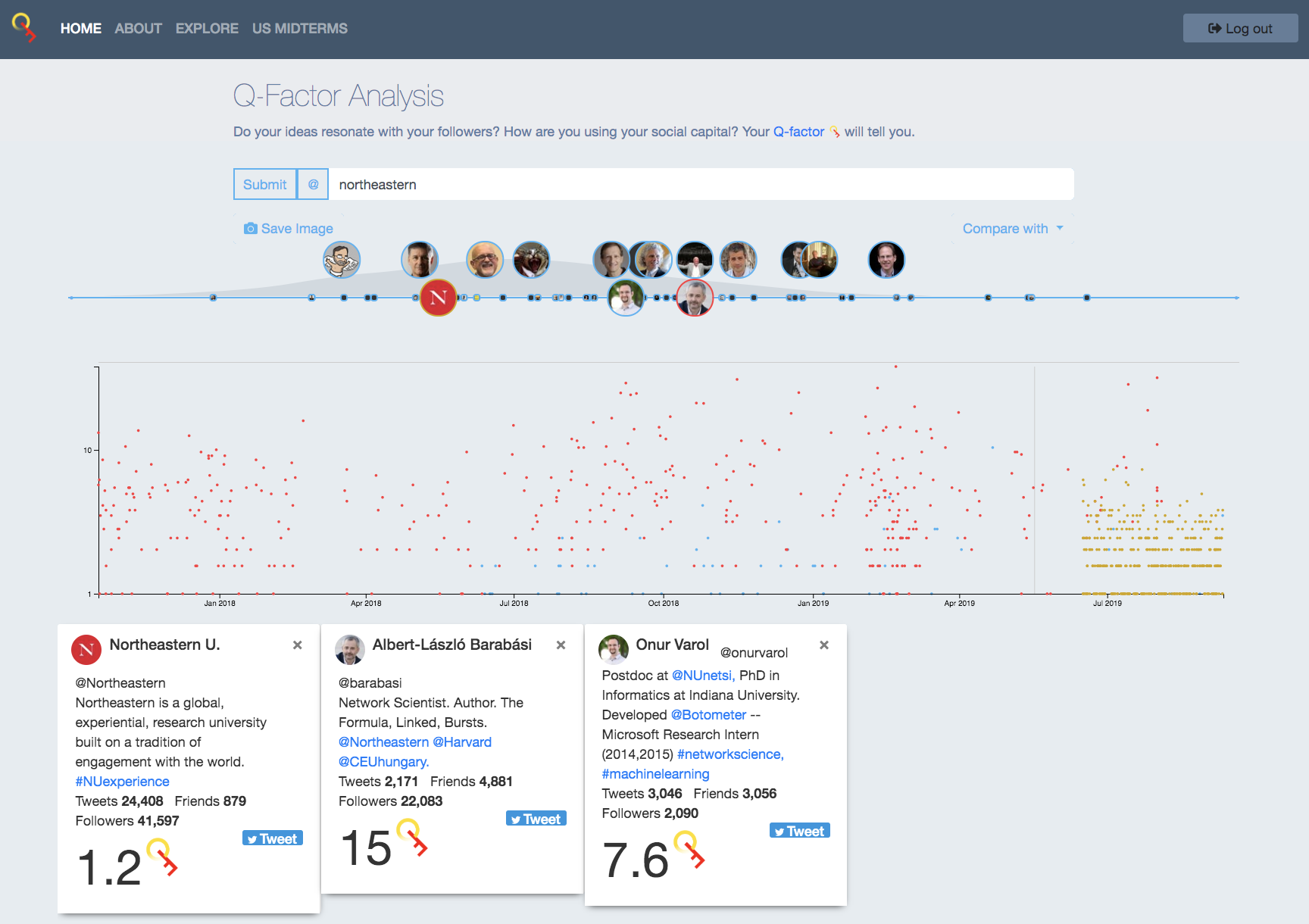
Here we define a metric, QT ,for Twitter user's ability to compose messages that engages its audience. The higher your QT, the more likely that any of your followers will find your message of sufficient interest to retweet it to their followers. QT is independent of the follower number, allowing us to meaningfully compare engagement for accounts of widely different popularity. Check mine at  @onurvarol
@onurvarol
News@Northeastern prepared a great coverage of our work and they designed an interactive story. You can find it here
L2P: Learning to Place
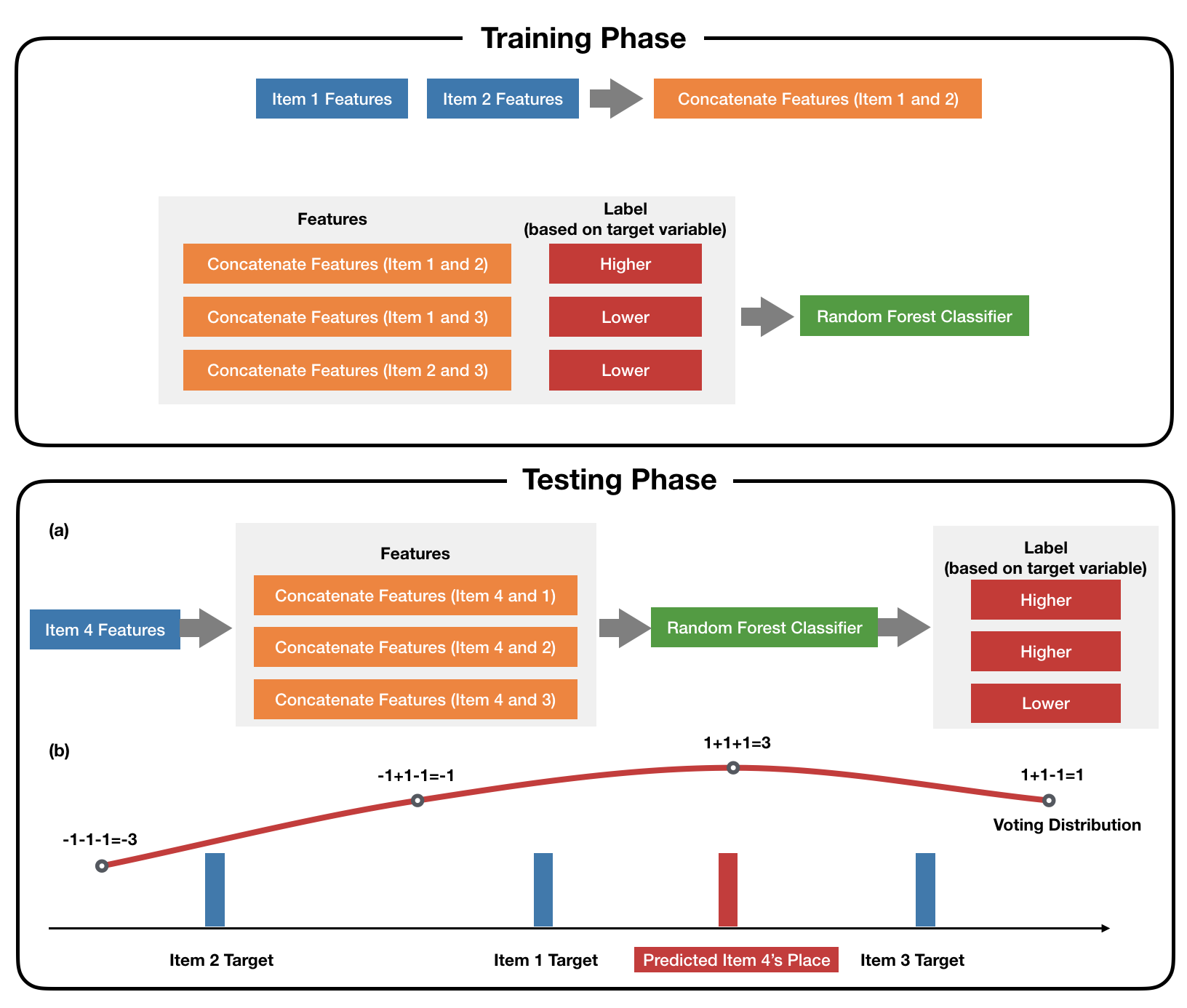
Many real-world prediction tasks have outcome (a.k.a. target or response) variables that have characteristic heavy-tail distributions. Examples include copies of books sold, auction prices of art pieces, etc. By learning heavy-tailed distributions, "big and rare" instances (e.g., the best-sellers) will have accurate predictions. Most existing approaches are not dedicated to learning heavy-tailed distribution; thus, they heavily under-predict such instances. To tackle this problem, we introduce Learning to Place (L2P) , which exploits the pairwise relationships between instances to learn from a proportionally higher number of rare instances. L2P consists of two stages. In Stage 1, L2P learns a pairwise preference classifier: is instance A > instance B?. In Stage 2, L2P learns to place a new instance into an ordinal ranking of known instances. Based on its placement, the new instance is then assigned a value for its outcome variable. Experiments on real data show that L2P outperforms competing approaches in terms of accuracy and capability to reproduce heavy-tailed outcome distribution. In addition, L2P can provide an interpretable model with explainable outcomes by placing each predicted instance in context with its comparable neighbors.
More information about L2P methodology and code, please visit project website.
Botometer -- Social bot detection

Sleep and well-being
I am using information inferred from online user behavior to captures relationship between real-world experience and mood with sleep quality. My ultimate goal is to capture factors effecting quality of sleep at the individual level.
Dream Analysis
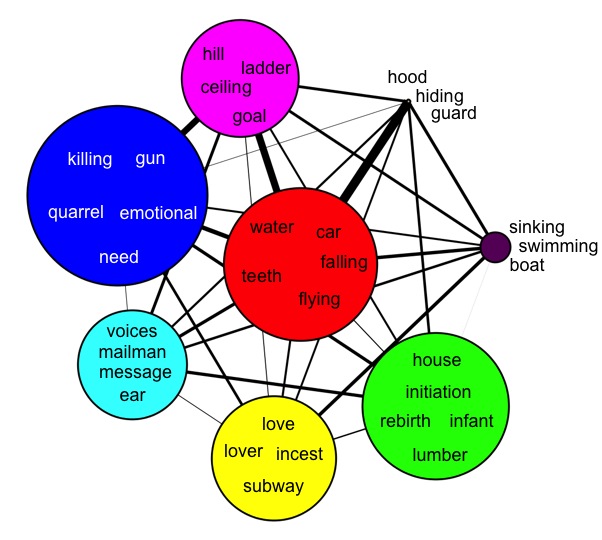
In this study, I introduce multiplex network of dream interpretations for English, Chinese and Arabic languages that represent different cultures from various parts of the world. We analyze communities in these networks, finding that symbols within a community are semantically related. The central nodes in communities give insight about cultures and symbols in dreams. Differences between network highlight interesting cultural patterns. For instance, we observed the dream symbol "woman" in Chinese network is one of the most central node of the network community consist of symbols with negative emotions and nightmares, cultural roots of which is explained by Jung in 1960s.
Explore dream network for English here
Previous Projects & Research
DESPIC
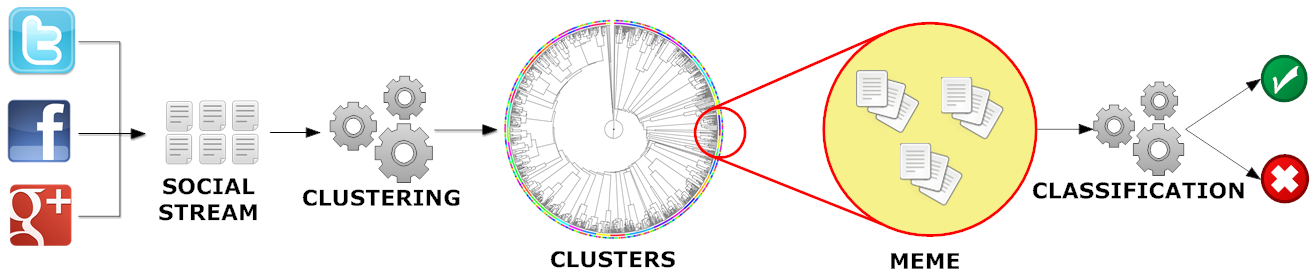
I have been working on several modules of this framework: (i) a clustering procedure that uses metadata to compute similarity between memes; (ii) a classification system that determines whether a meme is potentially an orchestrated campaign or a genuine, grassroots conversation; (iii) an anomaly detection system that tracks statistical patterns based on time, location, and user features to identify memes and tweets that needs additional inspection.
Social Protests
Modal analysis of Myosin II and Identification of Functionally Important Sites (M.Sc. Thesis 2012)

In this work, molecular dynamic results of Dictyostelium discoideum myosin II motor domain is used as test ground. Mode fluctuation distributions produced using MD results, fully harmonic models and a model with anharmonic corrections. Tensorial hermite polynomials are used in order to obtain distributions of modal fluctuations. Fluctuations on modal space are transformed back into real space and distribution of residual fluctuations is compared using KL divergence. Analysis results for ligand-bound and free myosin dynamics are used in order to demonstrate that the mode-coupling contributions alone highlight functionally important sites.
Social Network Analysis Using a Statistical Physics Approach (B.Sc. Thesis 2011)

EEG Data Classification and applications (B.Sc Thesis - 2010)

In this project, feature selection and classification of EEG signals for different cognitive actions is made. There are several methods for classifying them I tried different features and methods. SVM (Support Vector Machines) is one of the method that I used for classification.